지난 글에서 설명한 것과 같이 정적인 웹사이트는 requests만으로도 쉽게 HTML문서 전체를 볼 수 있다.
하지만, 동적으로 로딩되는 데이터가 있는 사이트는 requests로 크롤링 했을 때 내용이 거의 없게 된다.
그럴 때는 실제 브라우저에서 해당 페이지를 로딩하면서 크롤링을 수행하면 된다.
pip install selenium
selenium은 크롬, 엣지, 파이어폭스 등의 브라우저를 다 지원하긴 하지만, 설치되어 있고 사용할 브라우저에 맞는 브라우저 드라이버파일을 받아서 연동해주어야 한다.
크롬 등을 사용한 예는 많기 때문에 엣지로 하는걸 써보려고 한다.
먼저 edgedriver를 아래처럼 다운 받는다.

PC에 설치되어 있는 edge브라우저의 버전과 일치하는지도 확인해준다.

압축을 풀고 msedgedriver.exe 파일을 프로젝트 디렉토리로 이동시켜 준다.
그다음에 아래와 같은 6줄의 코드만 실행시키면,
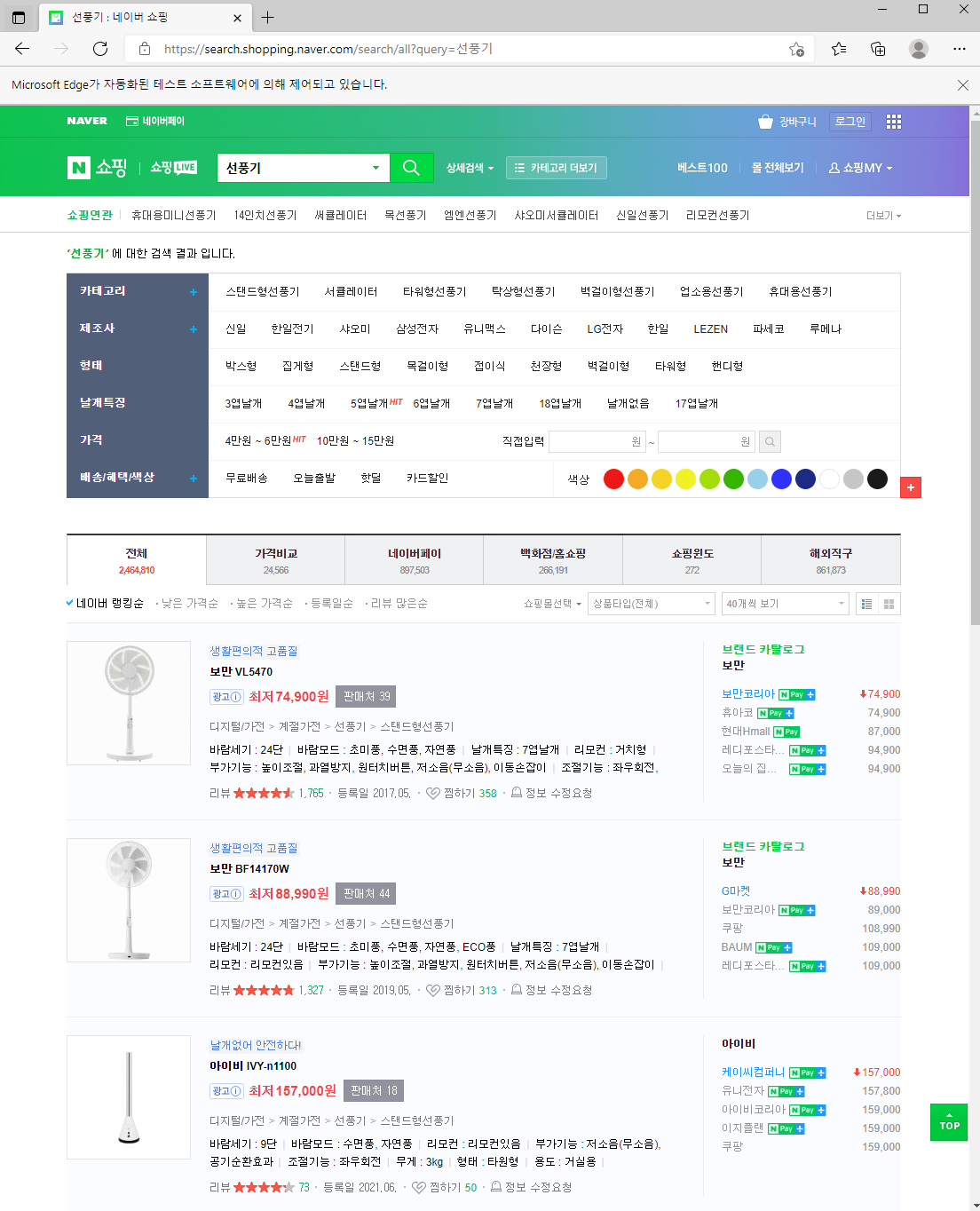
이런 화면이 나오게 된다.
페이지에서 텍스트만 출력하겠다면
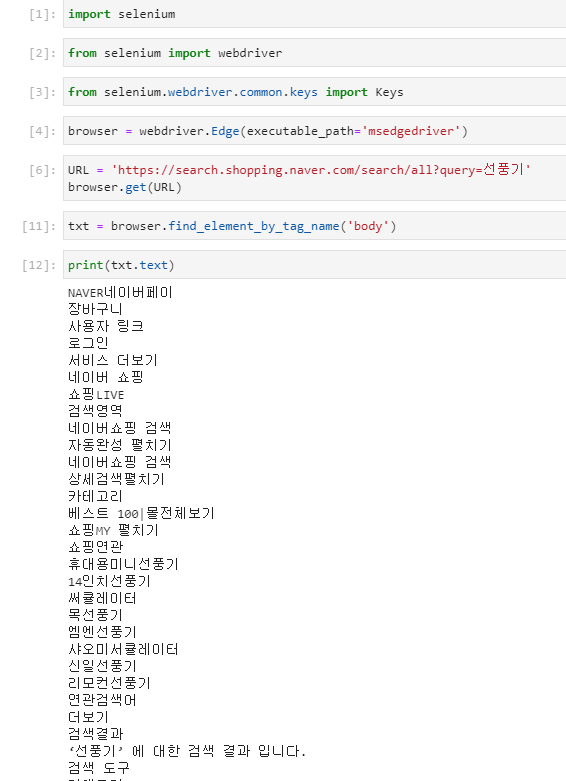
이렇게 하면 되고,
html소스를 그대로 가져오려면
아래처럼 추가하면 된다.

리스트 결과 중 상품을 선택하려면

둘 중 한가지 방법으로 가능하다.
elements를 element로 쓰면 list형으로 가져오지 않고 첫번째 한개만 가져온다.
여러개중 4번째것의 텍스트를 출력하면 아래처럼 나온다.

여기에서 상품명만 가져오겠다고 하면

이런식으로 가져올 수 있다.
이걸 기존에 했던 bs4를 이용한 방식으로 하려면,
아래와 같은 코드가 될 것이다. 하지만 페이지 로딩이 되고 javascript가 실행되기 전의 html소스만 가져왔기 때문에 원하는 결과를 얻을 수 없고, 에러가 발생한다.
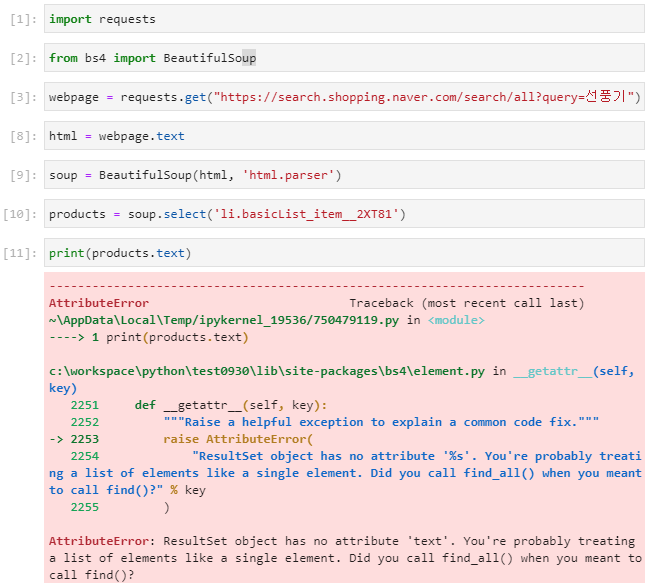
selenium은 브라우저를 열어서 콘트롤 하는 것이기 때문에 원하는 결과를 얻었으면 브라우저를 닫아주어야 한다. 특히 서버에서 실행시킬경우 headless옵션으로 하게 되기 때문에 눈에 보이지 않는 상태로 진행되니 browser.close()를 잊기 쉬운데 그러면 메모리 문제가 발생하기도 하고 몇번 크롤링을 반복하면 정상적으로 크롤링이 되지 않는 경우가 생긴다.
selenium방식의 크롤링을 사용하면, 해당 페이지에서 버튼 액션 등을 통해 타고 들어가서 안에 있는 컨텐츠까지 가져올 수 있기 때문에 실제 눈에 보이는 것과 같이 있는 그대로 가져올 수 있고, 티켓 예약이나 잔여백신 매크로 같은 것도 이런식으로 만드는 경우가 많다.
'기타 개발팁' 카테고리의 다른 글
| AWS S3 큰 파일 업로드 다운로드 하기 (0) | 2021.12.14 |
|---|---|
| 파이썬 크롤링 (3) - 크롤링한 정보 이메일로 보내기 (0) | 2021.09.30 |
| 파이썬 크롤링 (1) - 파이썬 크롤링을 위한 기본 세팅 (0) | 2021.09.30 |
| 라라벨 프로젝트 AWS Elastic Beanstalk을 이용해서 배포 환경 만들기 (0) | 2021.03.02 |
| AWS EC2 인스턴스 만들고 SSH putty 접속 (0) | 2021.03.01 |


