서버가 아닌 개인PC 윈도우에서도 많이들 하기 때문에 이 기준으로 간단히 써보고자 한다.
크롤링은 사실 모든 프로그래밍 언어로 다 가능하고, 크롤링의 기본은 웹페이지에 접속해서 해당 웹페이지를 읽는 것이기 때문에 아주 단순하다.
그런데 보통 크롤링이라고 했을 때는, 해당 크롤링 이후에 웹문서를 분석하고 필요 정보를 추출하고, 정보를 보관하고 배포하는 정도까지도 뭉뚱그려서 표현하기 때문에 쉽다가도 어려워지기도 한다.
이글에서는 단순히 웹페이지를 읽고, 필요 텍스트를 추출하는 정도까지만 다루려고 한다.
1. 소프트웨어 설치
파이썬 크롤링이니까 파이썬을 설치해야 된다. cmd창에서 python이나 python3, py 같은 명령을 실행시켜서 작동이 안되면 python이 설치되어 있지 않거나 python이 어딘가에 있지만 path가 설정되어 있지 않은거다. python이 없었다고 전제하고, www.python.org 에 가서 다운로드 받으면 된다.

설치할 때 체크박스를 잘 보고 path에 추가까지 해주는게 좋다.
파이썬이 설치 됐으면 cmd창을 열고 python이라고 쳐본다.
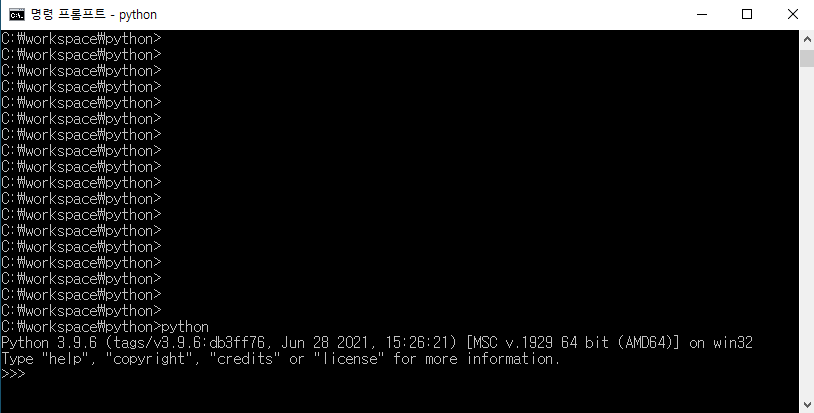
이런식으로 나오면 문제가 없이 설치된 것이고, Ctrl-Z로 빠져나온다.
그다음에는 필수적이지는 않지만, 필수에 가까운 가상환경을 만들어야 한다.
가상환경은 여러 프로젝트를 할때 파이썬의 모듈들의 dependency관리 차원에서 필요한데,
설명하려면 길어지니, 일단은 anaconda라든지 venv같은것을 쓰면 된다.
파이썬 마저도 3버전이나 2버전을 왔다갔다 하면서 쓰려면 파이썬 설치 이전에 가상환경 내에서만 파이썬을 설치할 수도 있다. 하지만, 뭐 그정도까지 할게 아니라면 파이썬 최신버전을 PC에 설치해놓고 쓰는게 더 편리하고 빠를 수 있다.
아무튼 가상환경 툴도 몇개 있지만 venv에 대해서만 이야기를 하려고 하고,
cmd창에서 프로젝트 디렉토리를 하나 만들고 거기에 가서 python -m venv . 이라고 치면
venv가 해당 프로젝트 디렉토리 내에 설치된다. 하지만 가상환경으로 아직 들어간 상태는 아니므로
Script\activate.bat 를 실행시키면 되고, 빠져나올 땐 deactivate.bat를 고르면 된다.
그리고 나서 pip install 등으로 원하는 모듈을 맘껏 인스톨 하고, 가상환경 빠져나오고 다른 프로젝트에서 또 하고 싶은 모듈 다 설치하고 나오고 그렇게 쓰면 된다.
크롤링 프로젝트에선 jupyter notebook을 활용하기로 했으니 venv가 activate된 상태에서 pip install jupyterlab 을 해준다. 사실 이름이 주피터노트북에서 주피터랩으로 바뀌었다.
설치가 됐으면 jupyter-lab 을 실행하면 된다.
실행하면 브라우저에서 아래와 같은 화면이 나온다.

Console보다는 Notebook이 쓰기 편하니 Notebook에서 Python 3을 누른다.
그러면 아래와 같은 일종의 코드에디터 화면이 나온다. 한줄한줄 단독으로 실행시켜볼 수 있어서 편리하다.
Ctrl-Enter를 누르면 해당 행이 실행이 되고, Shift-Enter를 누르면 개행이 된다. 삽입개행은 Alt-Enter.
파이썬 코드 뿐만 아니라 cmd창에서 했던 pip install 같은 작업도 notebook 상에서 실행 가능해서 더 편리하다.
크롤링에는 requests와 beautiful soup 모듈을 많이 쓰기 때문에 남들처럼(?) pip install bs4를 해주면 된다. requests는 기본모듈이라 설치가 필요없다.
사실 구분하자면 requests는 웹페이지 전체 크롤링이고, bs4에서는 requests가 가져온 문서의 분석 및 정보추출 같은 역할을 한다고 이해하면 쉽다.
딱 아래 3줄만 실행해보면 원하는 URL의 HTML문서를 그대로 가져올 수 있다.
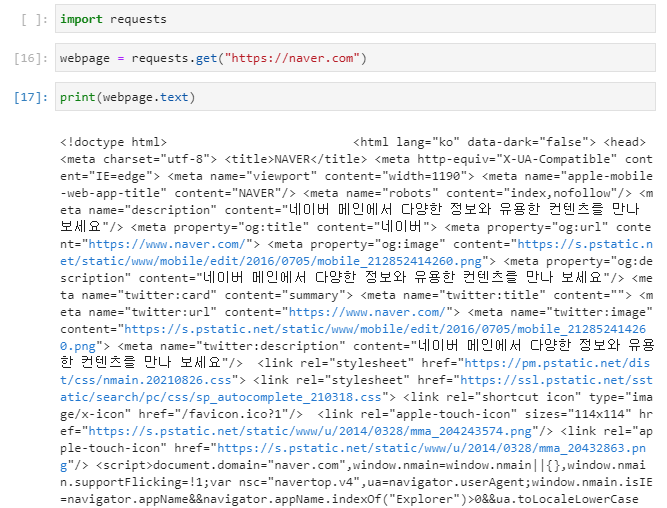
여기에서 추가로 원하는 정보를 찾으려면 bs4를 쓰면 된다.
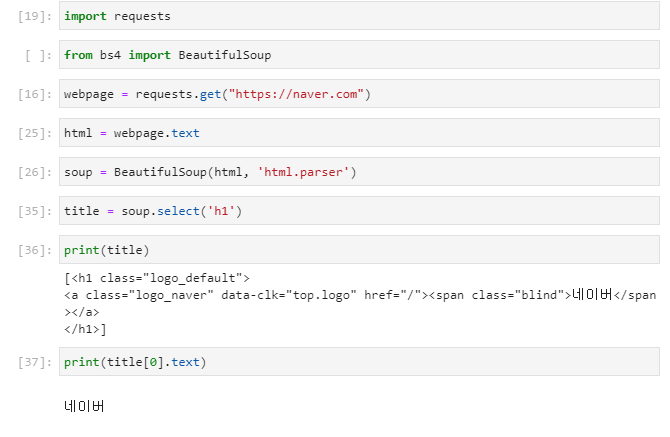
아무래도 정보 찾기가 빠질 수 없기 때문에 select를 많이 쓰게 되고, 원하는 html 태그나 class, id등을 지정하는 방식으로 찾게 된다. 위에서는 네이버 메인화면에서 h1태그를 찾고 해당 html 부분과 그 안에 들어있는 텍스트만 추출해서 출력하는 코드를 테스트해보았다.
select로 찾으면 배열로 나오기 때문에 결과가 1개라도 [0] 식으로 선택을 해주어야 하고, 한개만 선택하려면 select_one을 쓰면 된다.
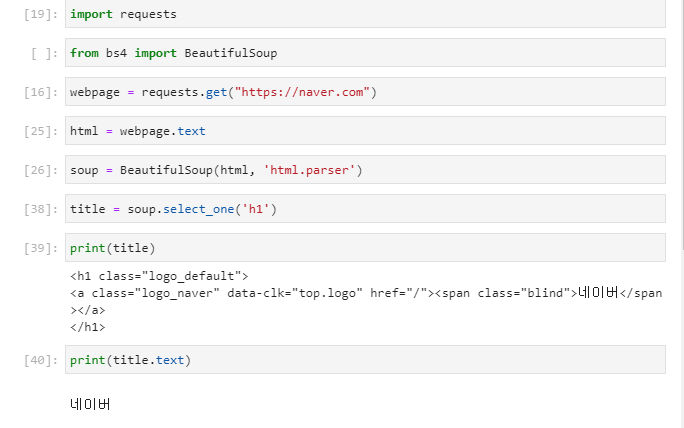
.text와 .string이 다른데 string은 정확히 해당 태그에 직접 종속된 텍스트가 있어야 출력이 되고, text는 하위 태그에 딸려도 출력이 된다. 그래서 위의 경우 title.text는 <h1>아래에 <a> 아래에 네이버라는 텍스트가 있어도 출력되지만,
string으로 출력되게 하려면 처음부터 select_one('h1 > a') 같은 식으로 처음부터 a태그를 선택해줘야 한다.
text대신에 get_text()로도 똑같이 작동한다고 한다.
select와 select_one 대신에 find_all과 find를 사용할 수도 있는데 결과에 큰 차이는 없다.
대신 select의 경우 css finder식으로 'h1 > a' 같이 쓰는데 find로 하려면 .find('h1').find('a') 이렇게 한단계씩 들어가 줘야 한다. 그래서 보통은 쓰기 편한 select를 더 많이 쓰게 되는 것 같다.
실전적인 예로서, 디씨인사이드의 실시간 베스트 중에서 제일 위에 있는 게시물 한개의 제목을 가져오려면
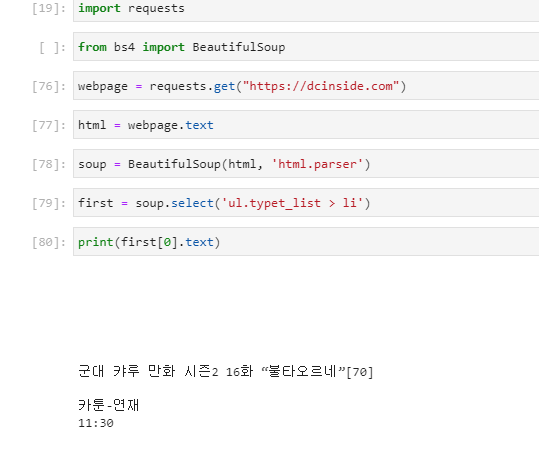
위와 같이 해주면 된다.
카테고리와 시간이 같이 뽑혀나왔기 때문에 정말 제목만 가져오겠다면

와 같이 하면 된다.
몇분 후에 다시 같은 코드를 실행하면 순위가 바뀌어서

다른 결과가 나온다.
만약 원하는 것이 새로운 베스트 게시물이 1위가 되었을 때 알림을 준다든지 그런 서비스를 만들겠다면 주기적으로 크롤링을 해서 새로운 정보로 대체되었을 때 알림을 날려주면 된다.
물론 특정 사이트를 무단으로 반복해서 크롤링 하는 것은 문제가 되고, 반복하지 않고 한번만 하더라도 해당 콘텐츠를 무단으로 사용할 경우 문제가 되므로, 허락을 미리 받든지 허용이 된 곳에서만 한다든지 등 적법하고 문제 없는 방법으로 문제없는 웹페이지만을 크롤링 해야 한다.
기본적인 정적 웹페이지는 이런 방식으로 쉽게 크롤링해서 파싱하는 것이 가능하지만,
AJAX를 쓴 동적웹페이지는 조금 더 느리고 귀찮은 방법을 택해야 크롤링이 가능하다.
selenium을 많이 쓰는데 selenium을 활용한 케이스의 경우는 다음 글에서...
'기타 개발팁' 카테고리의 다른 글
| 파이썬 크롤링 (3) - 크롤링한 정보 이메일로 보내기 (0) | 2021.09.30 |
|---|---|
| 파이썬 크롤링 (2) - 동적 웹사이트 파이썬 크롤링 (0) | 2021.09.30 |
| 라라벨 프로젝트 AWS Elastic Beanstalk을 이용해서 배포 환경 만들기 (0) | 2021.03.02 |
| AWS EC2 인스턴스 만들고 SSH putty 접속 (0) | 2021.03.01 |
| MySQL MariaDB CPU 사용량 먹고 느려질 때 (0) | 2021.02.16 |


